# 如果提示缺少R包直接安装即可
rm(list = ls())
data("bmtcrr",package = "casebase")
str(bmtcrr)
## 'data.frame': 177 obs. of 7 variables:
## $ Sex : Factor w/ 2 levels "F","M": 2 1 2 1 1 2 2 1 2 1 ...
## $ D : Factor w/ 2 levels "ALL","AML": 1 2 1 1 1 1 1 1 1 1 ...
## $ Phase : Factor w/ 4 levels "CR1","CR2","CR3",..: 4 2 3 2 2 4 1 1 1 4 ...
## $ Age : int 48 23 7 26 36 17 7 17 26 8 ...
## $ Status: int 2 1 0 2 2 2 0 2 0 1 ...
## $ Source: Factor w/ 2 levels "BM+PB","PB": 1 1 1 1 1 1 1 1 1 1 ...
## $ ftime : num 0.67 9.5 131.77 24.03 1.47 ...37 Fine-Gray检验和竞争风险模型
竞争风险模型(Competing Risk Model)适用于多个终点的生存数据,传统的生存分析(survival analysis) 一般只关心一个终点事件(即研究者感兴趣的结局)。将其他事件均按删失数据(Censored Data)处理,要求个体删失情况与个体终点事件相互独立,结局不存在竞争风险。
竞争风险模型(Competing Risk Model) : 指的是在观察队列中,存在某种已知事件可能会影响另一种事件发生的概率或者是完全阻碍其发生,则可认为前者与后者存在竞争风险。
比如我们研究某药物和肠癌复发的关系,感兴趣事件是肠癌复发,但是研究过程中病人因为心梗死了,这样就观察不到感兴趣事件了,那心梗死亡就可以被叫做竞争风险事件。
37.1 加载数据和R包
探讨骨髓移植和血液移植治疗白血病的疗效,结局事件定义为复发,某些患者因为移植不良反应死亡,定义为竞争风险事件。
这个数据一共7个变量,177行。
Sex: 性别,F是女,M是男D: 疾病类型,ALL是急性淋巴细胞白血病,AML是急性髓系细胞白血病。Phase: 不同阶段,4个水平,CR1,CR2,CR3,Relapse。Age: 年龄。Status: 结局变量,0=删失,1=复发,2=竞争风险事件。Source: 因子变量,2个水平:BM+PB(骨髓移植+血液移植),PB(血液移植)。ftime: 生存时间。
# 竞争风险分析需要用的R包
library(cmprsk)37.2 Fine-Gray检验(单因素分析)
在普通的生存分析中,可以用log-rank检验做单因素分析,在竞争风险模型中,使用Fine-Gray检验进行单因素分析。
比如现在我们想要比较不同疾病类型(D)有没有差异,可以进行Fine-Gray检验:
bmtcrr$Status <- factor(bmtcrr$Status)
f <- cuminc(bmtcrr$ftime, bmtcrr$Status, bmtcrr$D)
f
## Tests:
## stat pv df
## 1 2.8623325 0.09067592 1
## 2 0.4481279 0.50322531 1
## Estimates and Variances:
## $est
## 20 40 60 80 100 120
## ALL 1 0.3713851 0.3875571 0.3875571 0.3875571 0.3875571 0.3875571
## AML 1 0.2414530 0.2663827 0.2810390 0.2810390 0.2810390 NA
## ALL 2 0.3698630 0.3860350 0.3860350 0.3860350 0.3860350 0.3860350
## AML 2 0.4439103 0.4551473 0.4551473 0.4551473 0.4551473 NA
##
## $var
## 20 40 60 80 100 120
## ALL 1 0.003307032 0.003405375 0.003405375 0.003405375 0.003405375 0.003405375
## AML 1 0.001801156 0.001995487 0.002130835 0.002130835 0.002130835 NA
## ALL 2 0.003268852 0.003373130 0.003373130 0.003373130 0.003373130 0.003373130
## AML 2 0.002430406 0.002460425 0.002460425 0.002460425 0.002460425 NA结果中1代表复发,2代表竞争风险事件。
第一行统计量=2.8623325, P=0.09067592,表示在控制了竞争风险事件(即第二行计算的统计量和P值)后,两种疾病类型ALL和AML的累计复发风险无统计学差异P=0.09067592。
第2行说明ALL和AML的累计竞争风险无统计学差异。
$est表示估计的各时间点ALL和AML组的累计复发率与与累计竞争风险事件发生率(分别用1和2来区分,与第一行第二行一致)。
$var表示估计的各时间点ALL和AML组的累计复发率与与累计竞争风险事件发生率的方差(分别用1和2来区分,与第一行第二行一致)。
37.2.1 图形展示结果
对于上述结果可以使用图形展示:
plot(f,xlab = 'Month', ylab = 'CIF',lwd=2,lty=1,
col = c('red','blue','black','forestgreen'))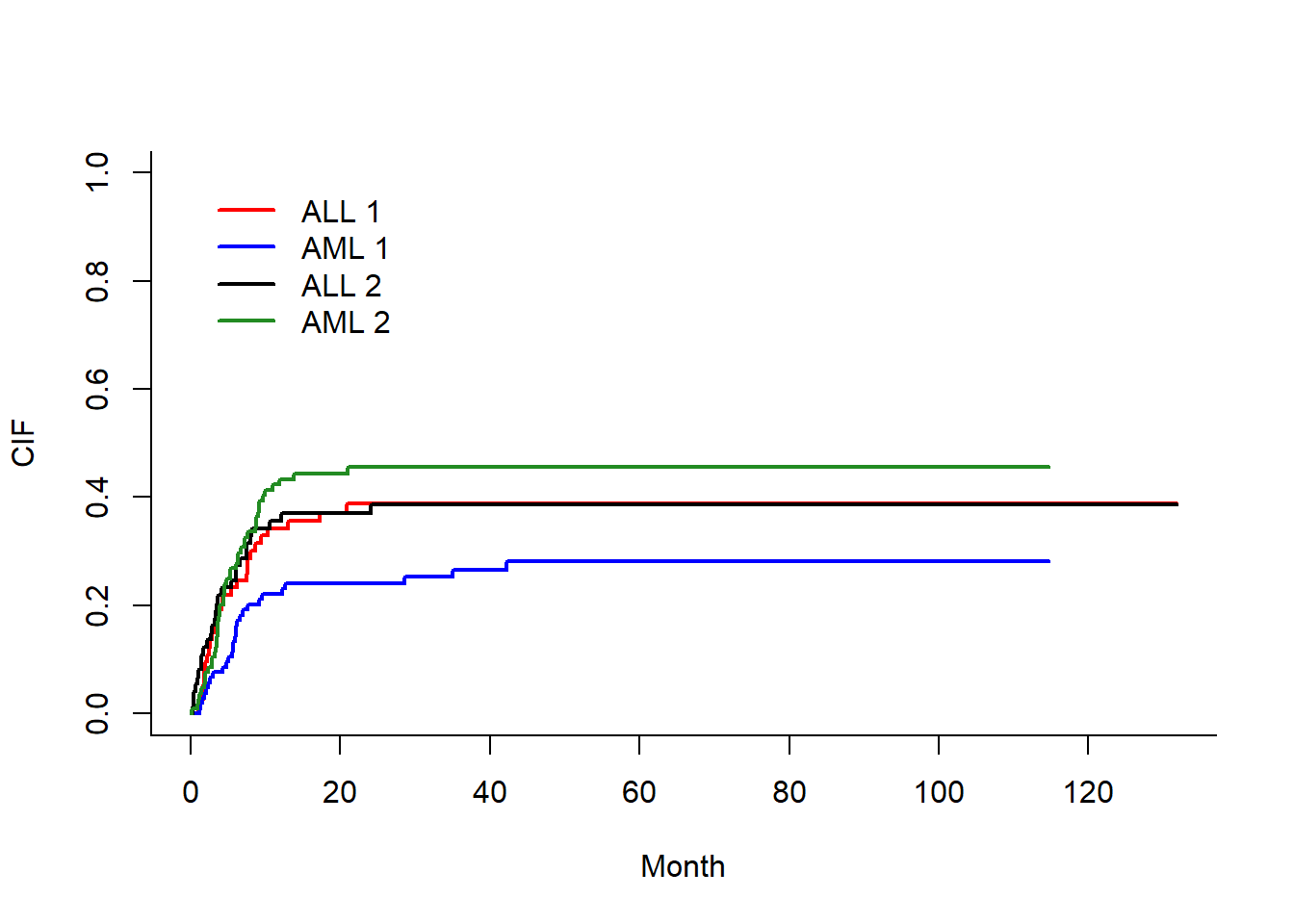
图形解读:
纵坐标表示累计发生率CIF,横坐标是时间。我们从ALL1对应的红色曲线和AML1对应的蓝色曲线可以得出,ALL组的复发风险较AML 组高,但无统计学意义,P=0.09067592。同理,ALL2对应的黑色曲线在AML2对应的草绿色曲线下方,我们可以得出,ALL组的竞争风险事件发生率较AML组低,同样无统计学意义,P=0.50322531。
简单来讲,这个图可以用一句话来概括:在控制了竞争风险事件后,ALL和AML累计复发风险无统计学差异P=0.09067592。
37.2.2 ggplot2
这个图不好看,非常的不ggplot,所以我们要用ggplot2重新画它!所以首先要提取数据,因为数就是图,图就是数。但是万能的broom包竟然没有不能提取这个对象的数据,只能手动来,太不优雅了!
# 提取数据
ALL1 <- data.frame(ALL1_t = f[[1]][[1]], ALL1_C = f[[1]][[2]])
AML1 <- data.frame(AML1_t = f[[2]][[1]], AML1_C = f[[2]][[2]])
ALL2 <- data.frame(ALL2_t = f[[3]][[1]], ALL2_C = f[[3]][[2]])
AML2 <- data.frame(AML2_t = f[[4]][[1]], AML2_C = f[[4]][[2]])
library(ggplot2)
ggplot()+
geom_line(data = ALL1, aes(ALL1_t,ALL1_C))+
geom_line(data = ALL2, aes(ALL2_t,ALL2_C))+
geom_line(data = AML1, aes(AML1_t,AML1_C))+
geom_line(data = AML2, aes(AML2_t,AML2_C))+
labs(x="month",y="cif")+
theme_bw()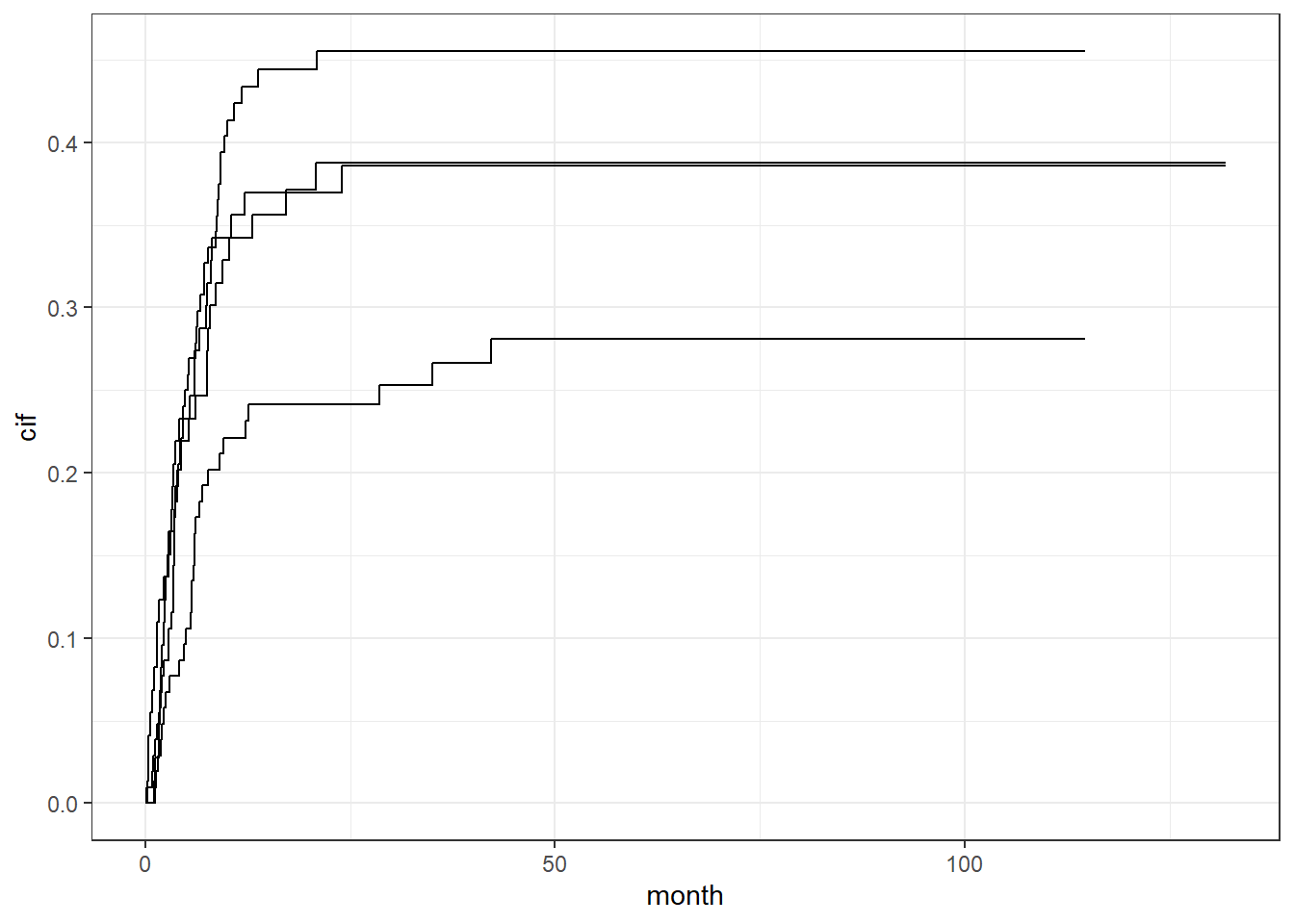
但是这种不好上色,所以我们美化一下,变成长数据再画图即可。
tmp <- data.frame(month = c(ALL1$ALL1_t,AML1$AML1_t,ALL2$ALL2_t,AML2$AML2_t),
cif = c(ALL1$ALL1_C,AML1$AML1_C,ALL2$ALL2_C,AML2$AML2_C),
type = rep(c("ALL1","AML1","ALL2","AML2"), c(58,58,58,88))
)
ggplot(tmp, aes(month, cif))+
geom_line(aes(color=type, group=type),size=1.2)+
theme_bw()+
theme(legend.position = "top")
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.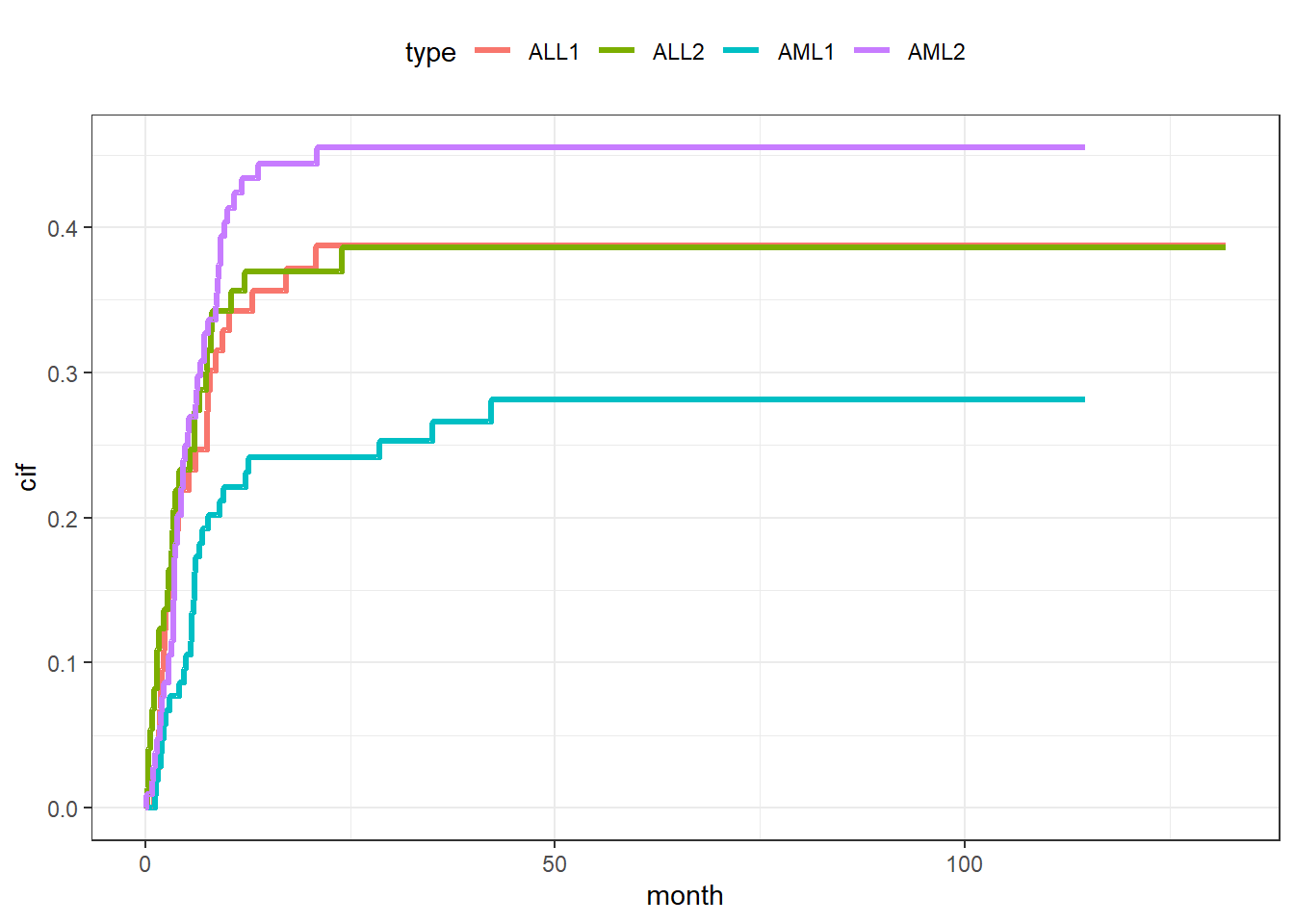
37.3 竞争风险模型(多因素分析)
做完了单因素分析,再看看竞争风险模型的多因素分析。
首先要把自变量单独放在一个数据框里,使用中发现一个问题,这里如果把分类变量变为因子型不会自动进行哑变量编码,所以需要手动进行哑变量编码!
但是我这里偷懒了,并没有进行哑变量设置!实际中是需要的哦!!
covs <- subset(bmtcrr, select = - c(ftime,Status))
covs[,c(1:3,5)] <- lapply(covs[,c(1:3,5)],as.integer)
str(covs)
## 'data.frame': 177 obs. of 5 variables:
## $ Sex : int 2 1 2 1 1 2 2 1 2 1 ...
## $ D : int 1 2 1 1 1 1 1 1 1 1 ...
## $ Phase : int 4 2 3 2 2 4 1 1 1 4 ...
## $ Age : int 48 23 7 26 36 17 7 17 26 8 ...
## $ Source: int 1 1 1 1 1 1 1 1 1 1 ...指定failcode=1, cencode=0, 分别代表结局事件1与截尾0,其他默认为竞争风险事件2。
# 构建竞争风险模型
f2 <- crr(bmtcrr$ftime, bmtcrr$Status, covs, failcode=1, cencode=0)
summary(f2)
## Competing Risks Regression
##
## Call:
## crr(ftime = bmtcrr$ftime, fstatus = bmtcrr$Status, cov1 = covs,
## failcode = 1, cencode = 0)
##
## coef exp(coef) se(coef) z p-value
## Sex 0.0494 1.051 0.2867 0.172 0.86000
## D -0.4860 0.615 0.3040 -1.599 0.11000
## Phase 0.4144 1.514 0.1194 3.470 0.00052
## Age -0.0174 0.983 0.0118 -1.465 0.14000
## Source 0.9526 2.592 0.5469 1.742 0.08200
##
## exp(coef) exp(-coef) 2.5% 97.5%
## Sex 1.051 0.952 0.599 1.84
## D 0.615 1.626 0.339 1.12
## Phase 1.514 0.661 1.198 1.91
## Age 0.983 1.018 0.960 1.01
## Source 2.592 0.386 0.888 7.57
##
## Num. cases = 177
## Pseudo Log-likelihood = -267
## Pseudo likelihood ratio test = 23.6 on 5 df,结果解读:在控制了竞争分险事件后,phase变量,即疾病所处阶段是患者复发的独立影响因素(p =0.00052)。