data("df_surv",package = "dcurves")
dim(df_surv)
## [1] 750 9
str(df_surv)
## Classes 'tbl_df', 'tbl' and 'data.frame': 750 obs. of 9 variables:
## $ patientid : num 1 2 3 4 5 6 7 8 9 10 ...
## $ cancer : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ ttcancer : num 3.009 0.249 1.59 3.457 3.329 ...
## $ risk_group : chr "low" "high" "low" "low" ...
## $ age : num 64 78.5 64.1 58.5 64 ...
## $ famhistory : num 0 0 0 0 0 0 0 0 0 0 ...
## $ marker : num 0.7763 0.2671 0.1696 0.024 0.0709 ...
## $ cancerpredmarker: num 0.0372 0.57891 0.02155 0.00391 0.01879 ...
## $ cancer_cr : Factor w/ 3 levels "censor","diagnosed with cancer",..: 1 1 1 1 1 1 1 2 1 1 ...44 测试集的决策曲线分析
突然发现我竟然从没专门介绍过测试集的决策曲线分析(其实在随机生存森林中介绍过)!直到前几天后台有人问我才意识到!
分类数据的决策曲线我给大家介绍了5种方法,生存数据的决策曲线我给大家介绍了4种方法,具体可参考:
今天就给大家介绍几种在测试集实现DCA的方法,其实也是用的上面介绍的方法。
除了决策曲线,还有校准曲线等,测试集的实现方法可参考:
关于校准曲线和决策曲线使用的概率问题,还进行了一些探讨,虽然枯燥,但是非常值得大家注意哈。画校准曲线和决策曲线时使用的是生存概率还是死亡概率
44.1 生存数据测试集
使用的数据集是包自带的df_surv数据集,一共有750行,9列,其中ttcancer是时间,cancer是结局事件,TRUE代表有癌症,FALSE代表没有癌症。
划分训练集测试集:
df_surv$cancer <- as.numeric(df_surv$cancer) # stdca函数需要结果变量是0,1
df_surv <- as.data.frame(df_surv) # stdca函数只接受data.frame
train <- sample(1:nrow(df_surv),nrow(df_surv) * 0.7)
train_df <- df_surv[train,]
test_df <- df_surv[- train,]
dim(train_df)
## [1] 525 9
dim(test_df)
## [1] 225 944.1.1 方法1:stdca.R
我这里选择方法是stdca.R,因为这种方法比较灵活,非常适合各种DIY。但是要注意:
这个网站之前可以免费下载
dca.r/stdca.r这两段脚本,但是现在已经不再提供该代码的下载,我把dca.r/stdca.r这两段代码已经放在粉丝QQ群文件,需要的加群下载即可。但是原网站下载的
stdca.r脚本在某些数据中会遇到以下报错:Error in findrow(fit,times,extend):no points selected for one or more curves, consider using the extend argument,所以我对这段脚本进行了修改,可以解决这个报错。但是需要额外付费获取,获取链接:适用于一切模型的DCA,赞赏后加我微信获取,或者加我微信转账获取。没有任何答疑服务,介意勿扰。另外,我在之前的推文中介绍过超多种绘制决策曲线的方法,你也可以选择其他方法。
library(survival)
# 加载函数
source("E:/R/r-clinical-model/000files/stdca.R")
# 构建一个多元cox回归
cox_model <- coxph(Surv(ttcancer, cancer) ~ age + famhistory + marker,
data = train_df)
# 计算1.5年的事件概率
train_df$prob1 <- c(1-(summary(survfit(cox_model, newdata=train_df), times=1.5)$surv))
# 这个函数我修改过,如果你遇到报错,可以通过添加参数 xstop=0.5 解决
aa <- stdca(data=train_df,
outcome="cancer",
ttoutcome="ttcancer",
timepoint=1.5,
predictors="prob1",
smooth=TRUE
)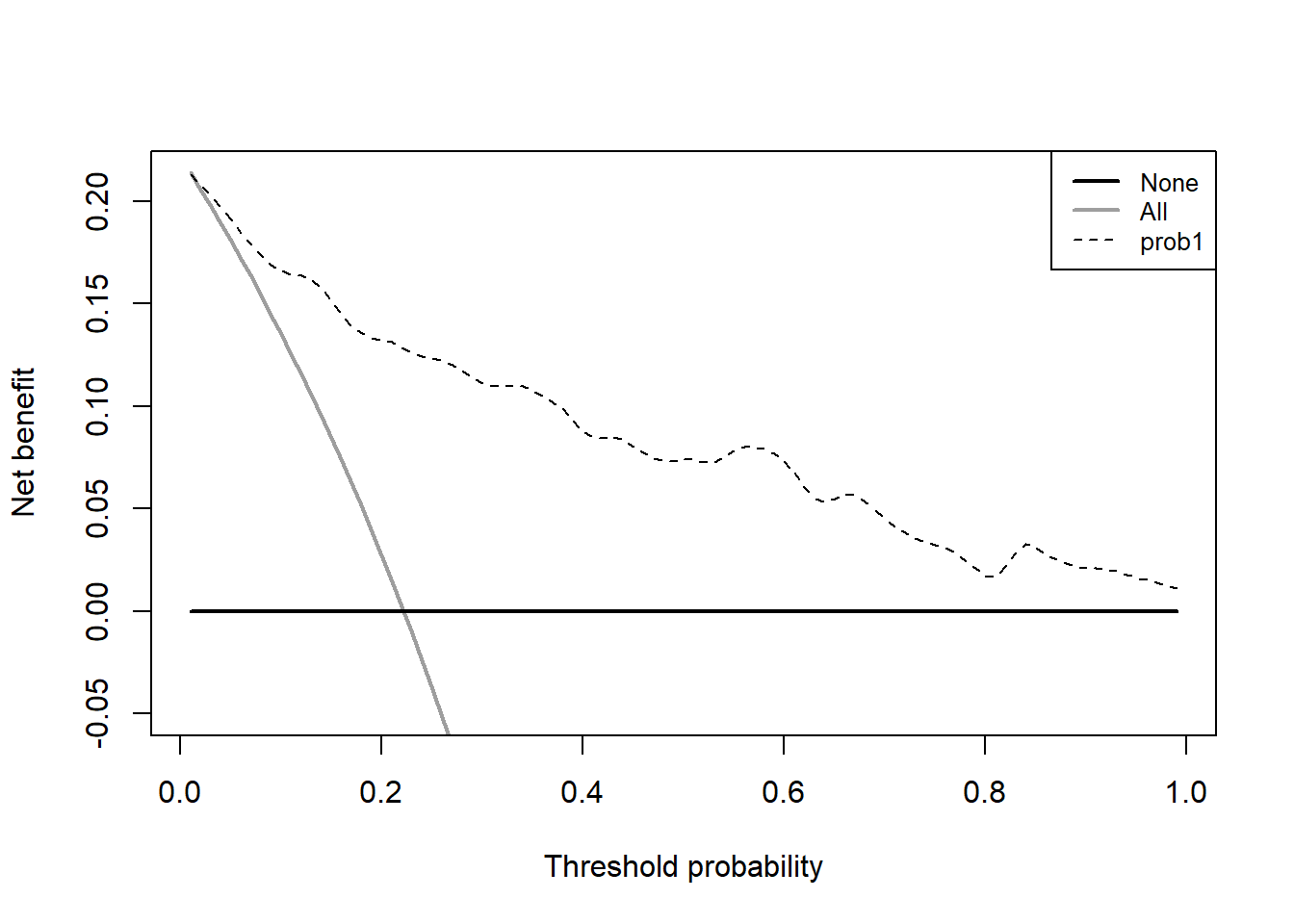
这个是训练集的决策曲线,这个是可以提取数据然后自己使用ggplot2绘制的,详情请参考上面的推文。
下面就是测试集的决策曲线分析了,非常简单:
# 计算测试集1.5年的事件概率
test_df$prob1 <- c(1-(summary(survfit(cox_model, newdata=test_df), times=1.5)$surv))
# 这个函数我修改过,如果你遇到报错,可以通过添加参数 xstop=0.5 解决
aa <- stdca(data=test_df,
outcome="cancer",
ttoutcome="ttcancer",
timepoint=1.5,
predictors="prob1",
smooth=TRUE
)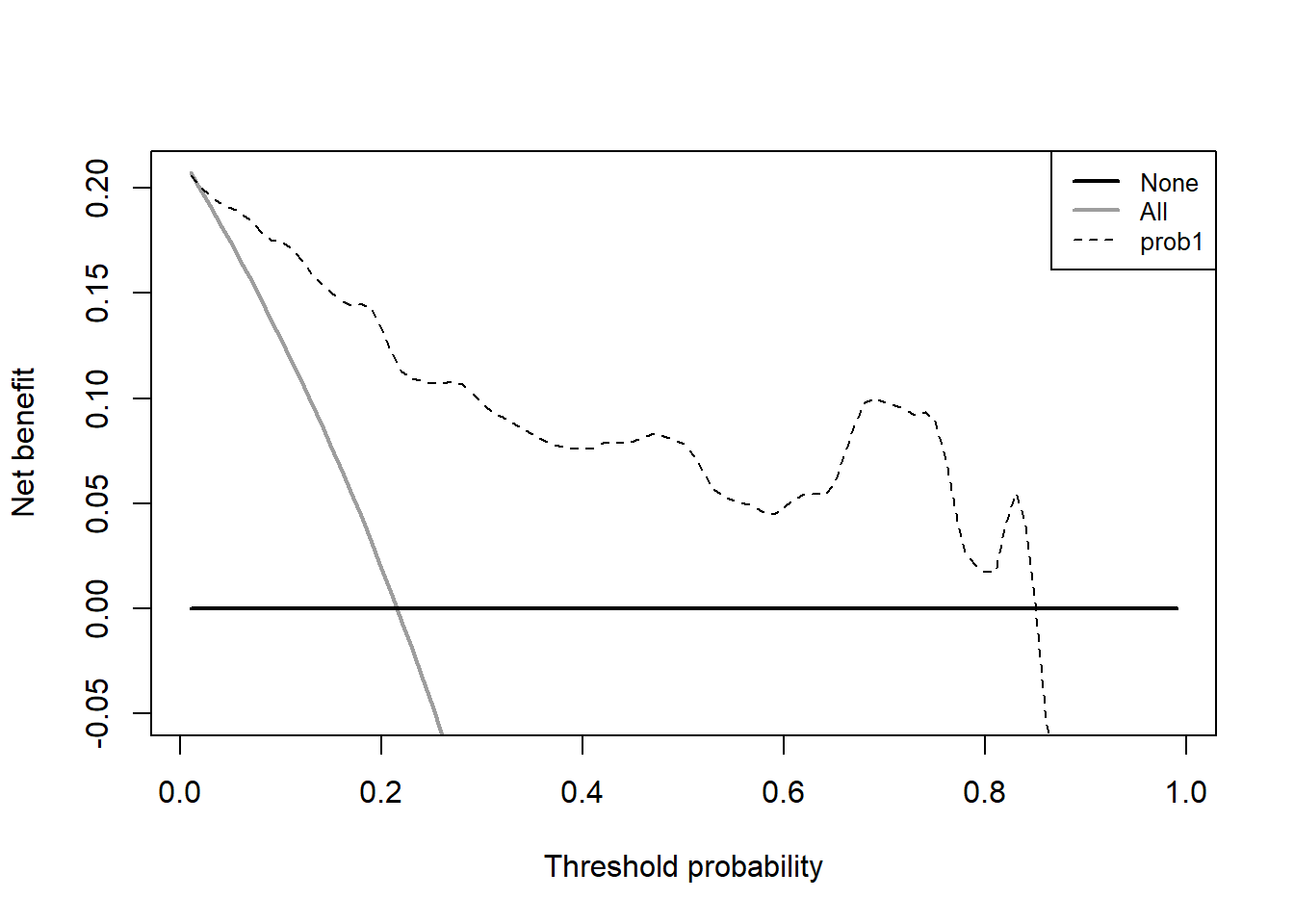
这个就是测试集的决策曲线分析了。
44.1.2 方法2:ggDCA
初学者最适合的方法了。对于同一个模型多个时间点、同一个时间点多个模型,都可以非常简单的画出来。
library(ggDCA)
# 构建一个多元cox回归
cox_model <- coxph(Surv(ttcancer, cancer) ~ age + famhistory + marker,
data = train_df)1行代码解决:
df <- ggDCA::dca(cox_model,
times = 1.5 # 1.5年,默认值是中位数
)
ggplot(df)
## Warning: Removed 128 rows containing missing values (`geom_line()`).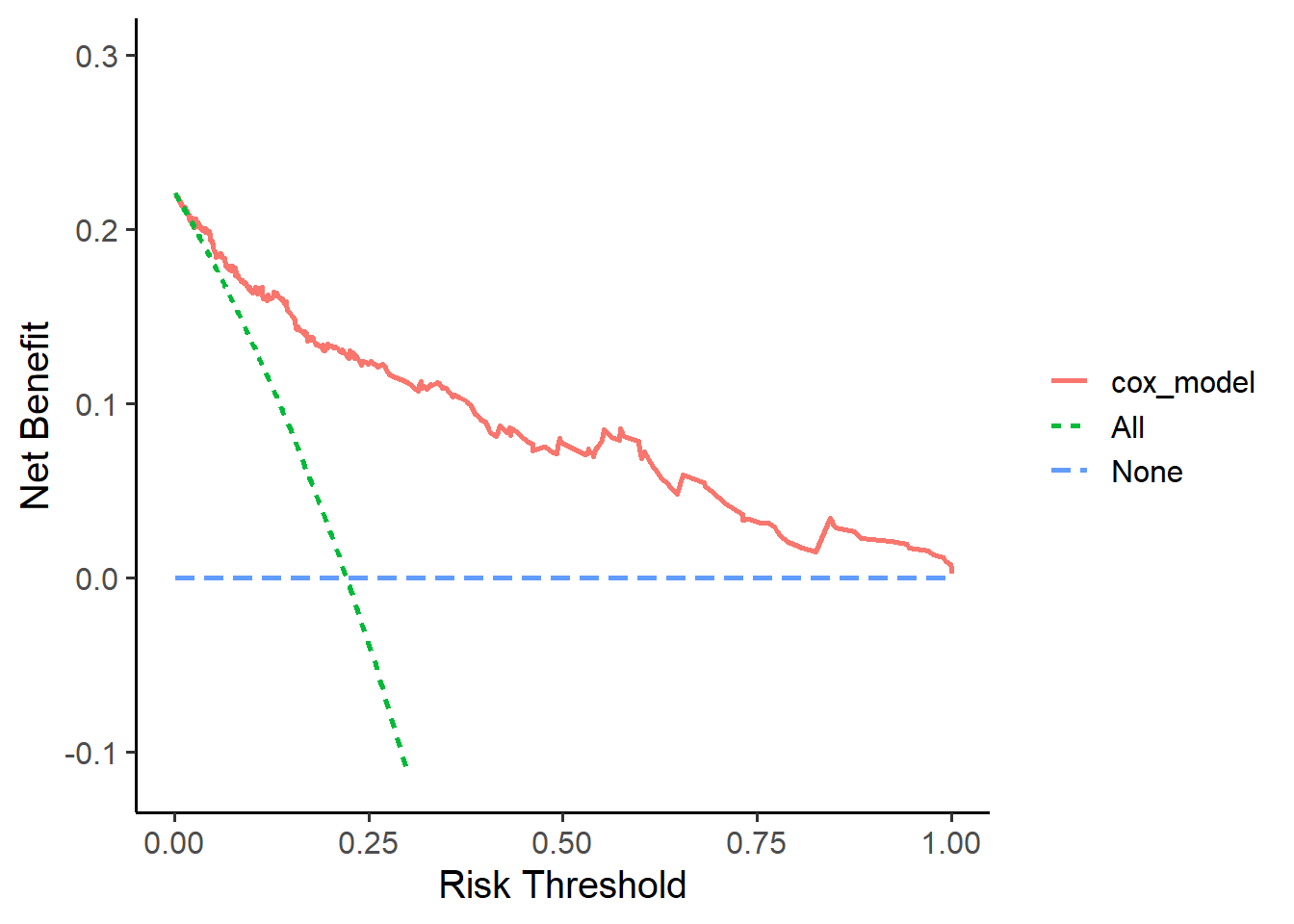
这个图也是可以美化的,具体还是参考上面的推文。这个图和我们用stdca.r画出来的图是一模一样的哈,只是图形的长宽比例和坐标轴的范围不同而已(stdca.r画出来的图还进行了平滑处理)。
测试集也是1行代码解决:
df <- ggDCA::dca(cox_model,
times = 1.5, # 1.5年,默认值是中位数
new.data = test_df
)
ggplot(df)
## Warning: Removed 184 rows containing missing values (`geom_line()`).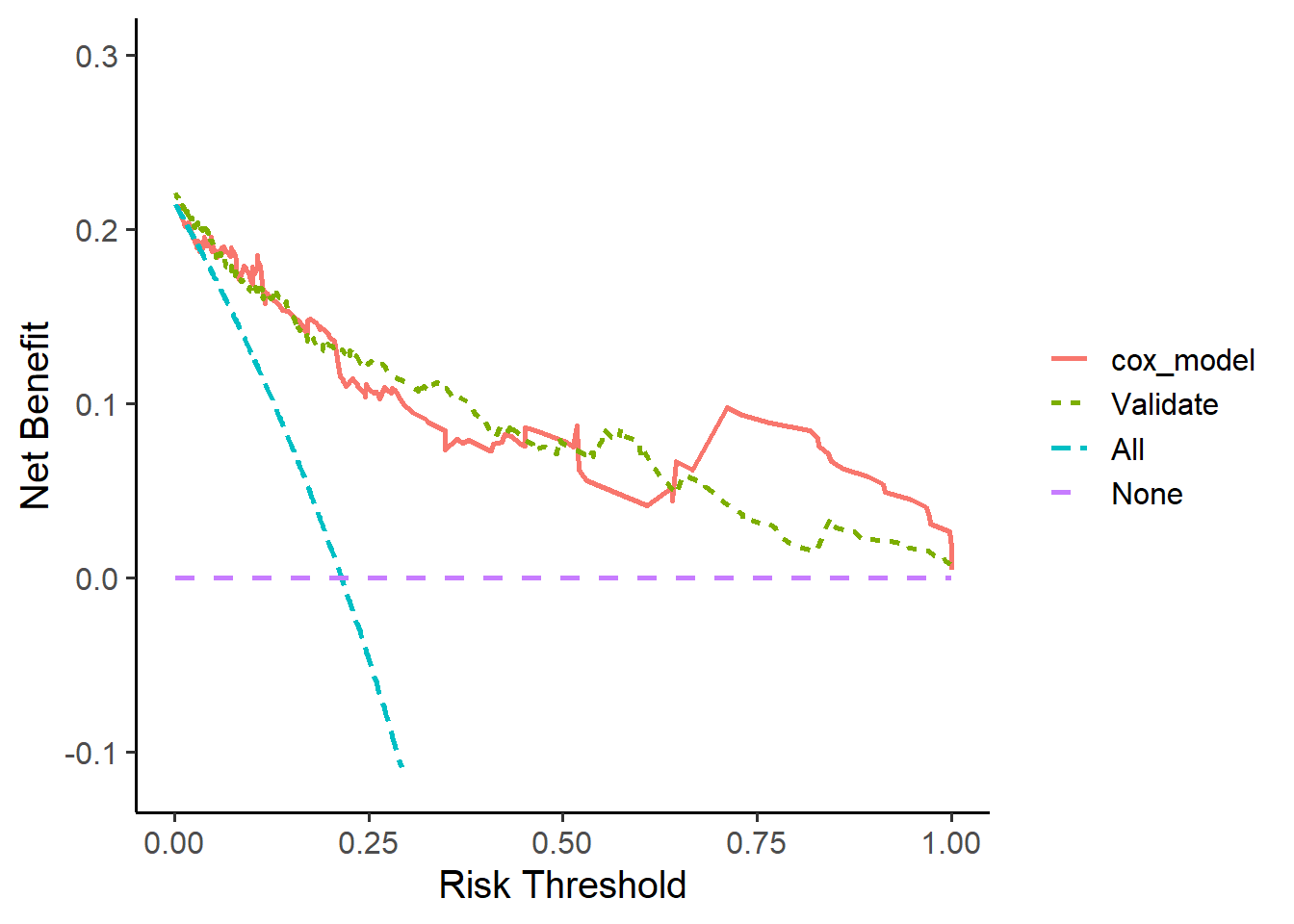
红色的那条是测试集的,validate是训练集的,你如果不想要可以自己提取数据画图。
是不是很easy呢?
44.2 分类数据测试集
这个数据集一共500行,6列,其中Cancer是结果变量,1代表患病,0代表没病,其余列是预测变量。
rm(list = ls())
data("dcaData",package = "rmda")
dcaData <- as.data.frame(dcaData)
dim(dcaData) # 500,6
## [1] 500 6
str(dcaData)
## 'data.frame': 500 obs. of 6 variables:
## $ Age : int 33 29 28 27 23 35 34 29 35 27 ...
## $ Female : num 1 1 1 0 1 1 1 1 1 1 ...
## $ Smokes : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ Marker1: num 0.245 0.943 0.774 0.406 0.508 ...
## $ Marker2: num 1.02108 -0.25576 0.33184 -0.00569 0.20753 ...
## $ Cancer : int 0 0 0 0 0 0 0 0 0 0 ...划分训练集测试集:
train <- sample(1:nrow(dcaData), nrow(dcaData)*0.7)
train_df <- dcaData[train,]
test_df <- dcaData[- train,]
dim(train_df)
## [1] 350 6
dim(test_df)
## [1] 150 644.2.1 方法1:dca.r
训练集的DCA:
source("./datasets/dca.r")
# 建立包含多个自变量的logistic模型
model <- glm(Cancer ~ Age + Female + Smokes + Marker1 + Marker2,
family=binomial(),
data = train_df
)
# 算出概率
train_df$prob <- predict(model, type="response")
# 绘制多个预测变量的DCA
aa <- dca(data=train_df, outcome="Cancer", predictors="prob",
probability = T,
xstop=0.35 # 控制x轴范围
)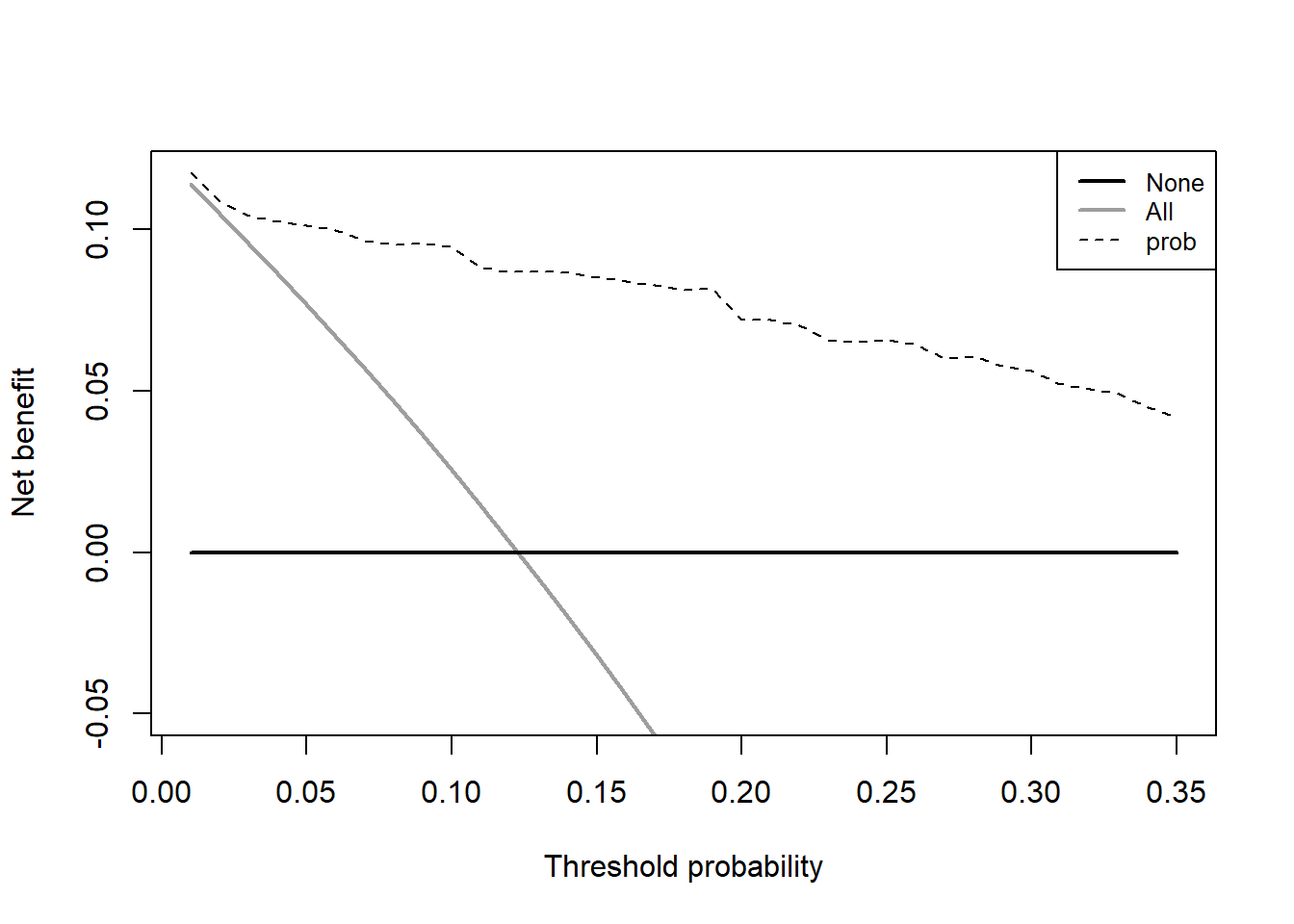
测试集的DCA:
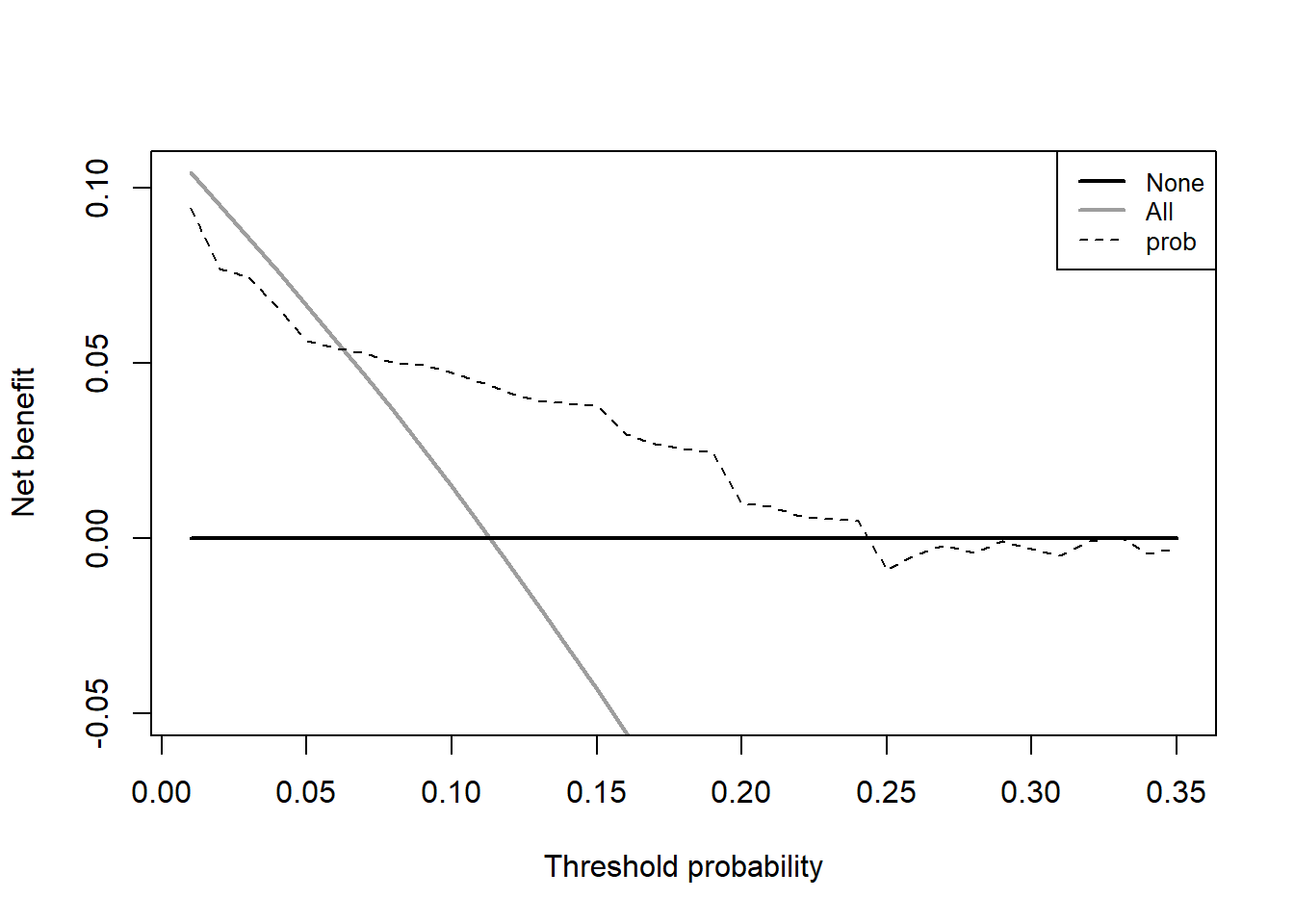
# 算出概率
test_df$prob <- predict(model, type="response", newdata = test_df)
# 绘制多个预测变量的DCA
aa <- dca(data=test_df, outcome="Cancer", predictors="prob",
probability = T,
xstop=0.35 # 控制x轴范围
)
44.2.2 方法2:ggDCA
训练集的DCA:
library(ggDCA)
# 建立包含多个自变量的logistic模型
model <- glm(Cancer ~ Age + Female + Smokes + Marker1 + Marker2,
family=binomial(),
data = train_df
)
aa <- ggDCA::dca(model)
ggplot(aa)
## Warning: Removed 73 rows containing missing values (`geom_line()`).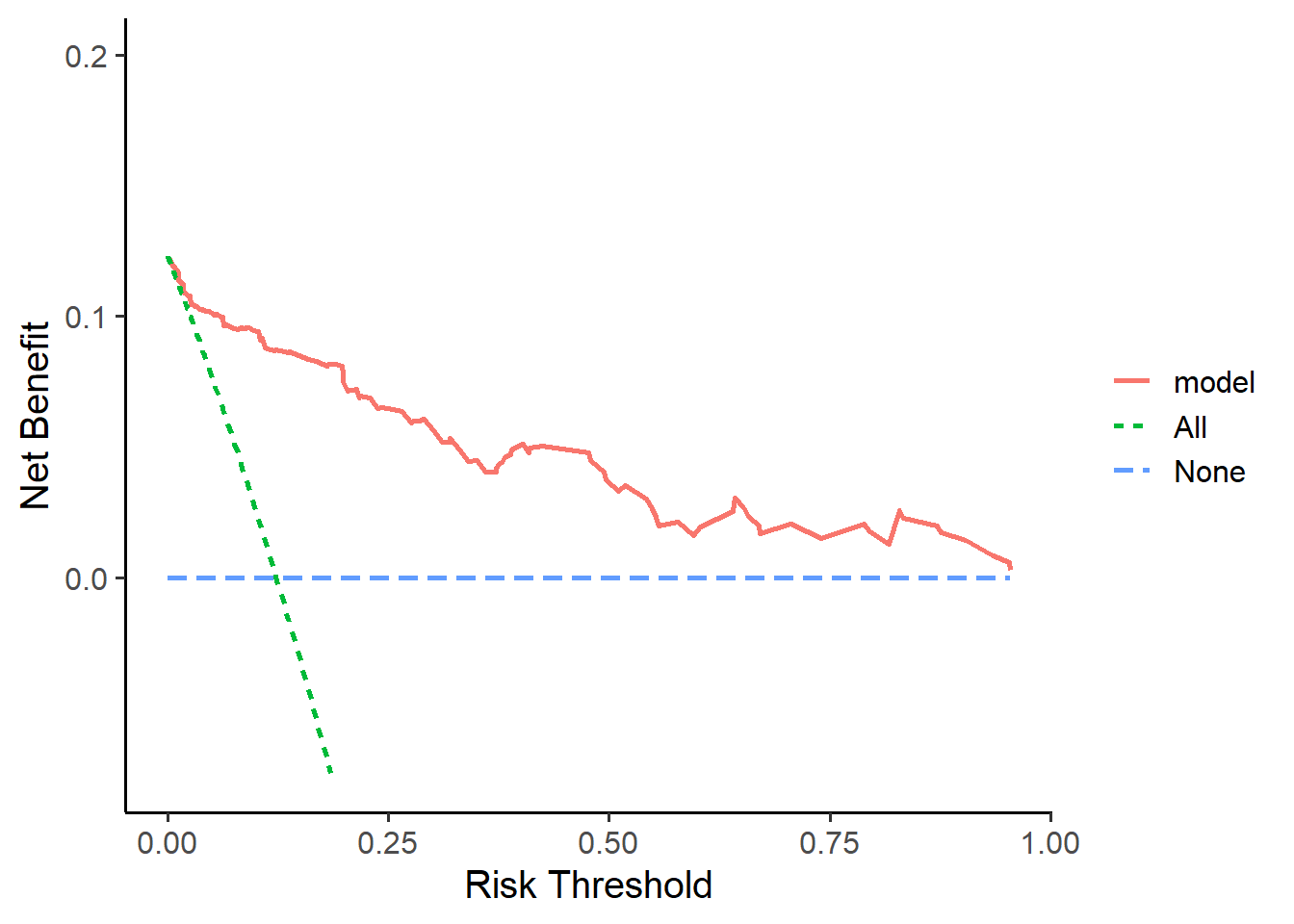
测试集的DCA:
aa <- ggDCA::dca(model,new.data=test_df)
ggplot(aa)
## Warning: Removed 120 rows containing missing values (`geom_line()`).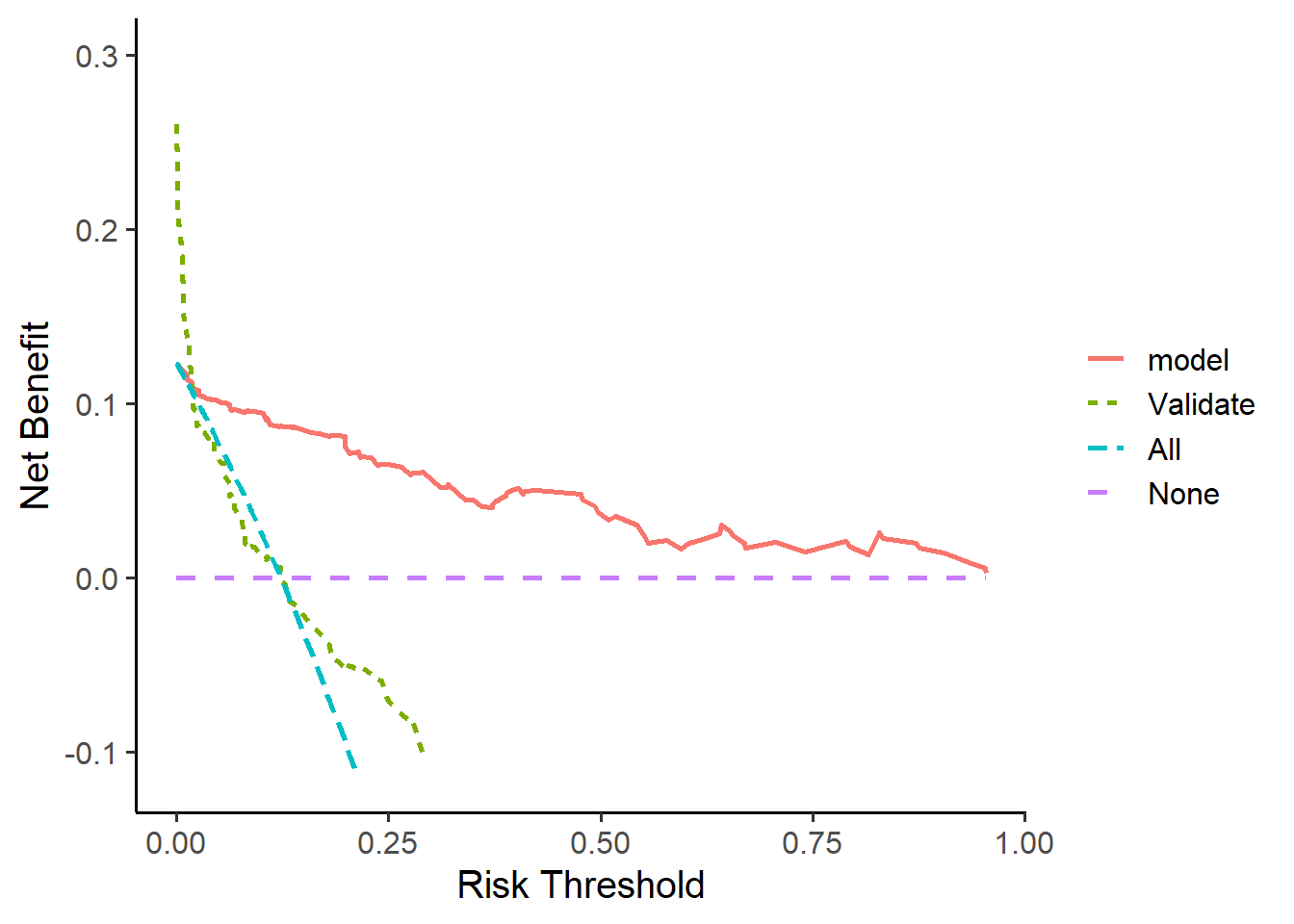
红色的是测试集的DCA曲线,因为坐标范围问题,看起来不太好看,但是你可以自己提取数据重新画。这里就不演示了。
后台回复决策曲线即可获取决策曲线推文合集;回复校准曲线即可获取校准曲线推文合集~